Contact Us


An overview of LLM architecture, covering foundation models, Transformer design, context length, and the rise of context engineering in real industrial workflows.
Foundation models form the structural bedrock of modern AI systems. Trained on massive, heterogeneous datasets, they develop a general capability to understand and generate human language without being restricted to a single downstream task.
The key advantage of this design lies in generalization—a single, unified model can be adapted across tasks through fine-tuning or prompt engineering, without the need for structural changes.
Historically, natural language systems were built as narrow, task-specific architectures—one for translation, another for sentiment analysis, yet another for entity recognition. Foundation models such as GPT, LLaMA, and PaLM changed that paradigm by introducing a unified Transformer backbone capable of scaling across domains.
This shift was enabled by advances in model architecture, distributed training, and hardware acceleration—collectively transforming AI from a collection of specialized tools into a general-purpose platform.
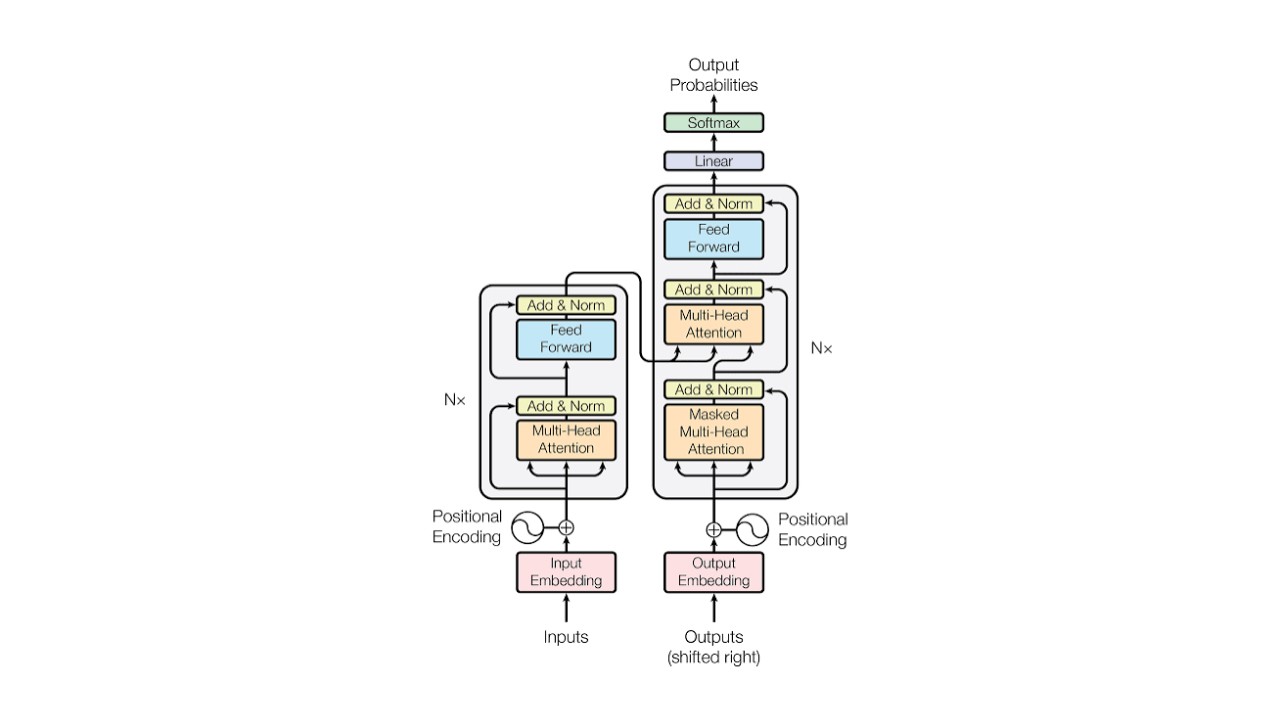
The Transformer remains the defining innovation of modern LLMs. Introduced by Google in 2017, its core contribution lies in replacing sequential computation with self-attention, enabling parallel processing and long-range semantic reasoning.
Self-attention allows the model to evaluate relationships between all tokens in an input sequence simultaneously, capturing contextual dependencies that recurrent networks struggled with. Combined with multi-head attention, Transformers can interpret multiple semantic perspectives at once—grammar, meaning, and discourse-level context—within the same pass.
Architecturally, Transformers can be configured as encoder–decoder systems (e.g., T5, BART) or as decoder-only architectures (e.g., GPT). The latter has become the dominant design for generative models, using autoregressive token prediction to produce fluent, contextually coherent output.
This modularity, scalability, and efficiency make the Transformer the enduring core of nearly every LLM in use today.
The context length, a model's effective working memory, determines how much information it can process at once. While early models struggled with a few thousand tokens, recent architectural leaps have dramatically expanded this frontier. Recent large models can easily expand and handle over 100k tokens.
This expansion is not just about size; it's about efficiency. The original Transformer's self-attention scales quadratically with sequence length, making large contexts computationally prohibitive. To overcome this, modern architectures employ techniques like sparse attention, efficient architectural designs like Mixture of Experts (MoE), and extrapolation methods, enabling models to find and reason over specific details within massive volumes of information. However, a large window is not a panacea, as the effective use of that memory is often the true bottleneck.
As context windows expand, the focus shifts from prompt engineering (crafting a single query) to Context Engineering. This is the discipline of designing and building dynamic systems to fill the context window with the right information, in the right format, at the right time. An LLM's context is not just the user's question; it's a curated package of system instructions, chat history, tool definitions, and data retrieved from external sources (like RAG).
Context engineering is critical because of a phenomenon known as Context Rot. Research shows that model performance can degrade as input length increases, even if the correct information is present. When critical data is buried deep in the middle of a long, noisy context (a "needle in a haystack" problem), models may fail to retrieve or reason over it, suffering from recency bias or a "lost in the middle" effect. Simply having a 1-million-token window doesn't guarantee the model will effectively use it.
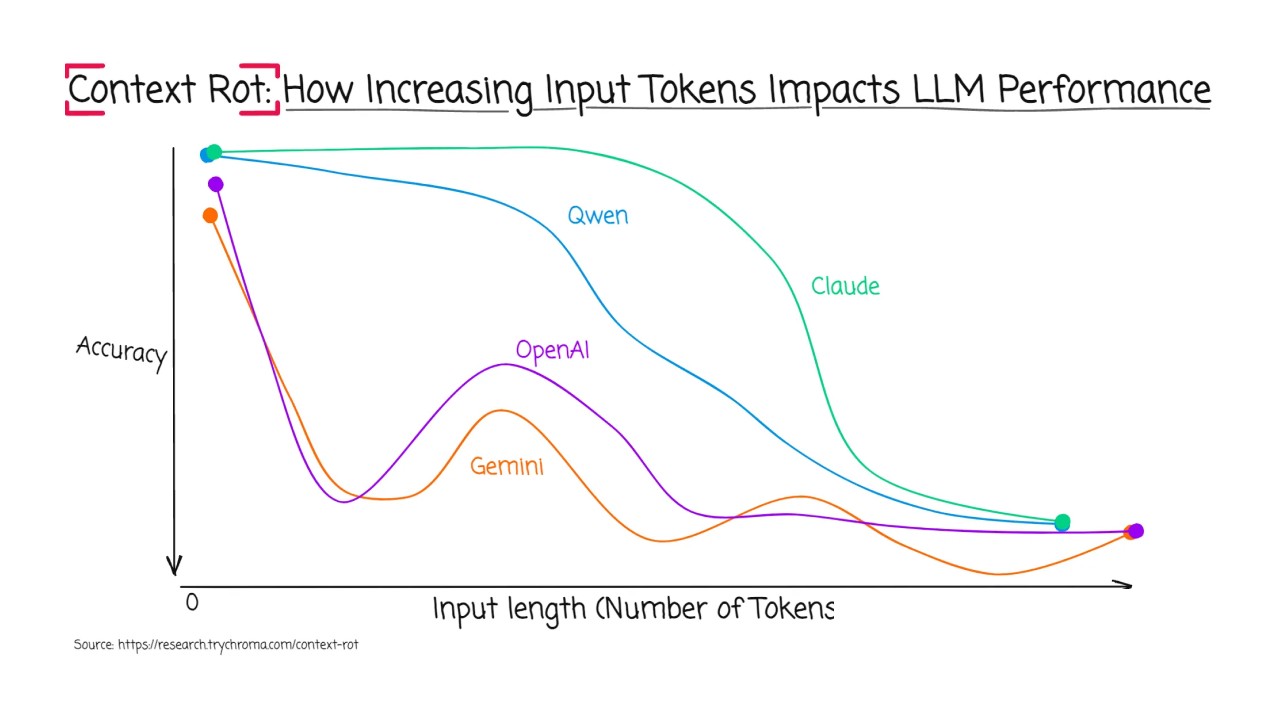
Context rot presents a major challenge in industrial applications, such as equipment mapping. A large facility may have tens of thousands of raw data "tags" (e.g., 'T-101-Feed-Temp') in a system like AVEVA PI. Asking an LLM to "map all tags to their asset hierarchy" by feeding it the entire database would fail, as the model would be overwhelmed by noise and suffer from context rot.

The BKOai Contextualization Agent solves this by acting as an advanced context engineer. Instead of "stuffing" the context, the Contextualization Agent utilizes a dynamic memory system so that:
The agent performs:
The result is a continuously evolving knowledge graph that links tags, equipment, and documentation—transforming industrial data silos into a unified layer of operational intelligence.